Supervised And Unsupervised Machine Learning Projects
Supervised machine learning is a type of machine learning in which the model is trained on labeled data, meaning that the correct output or classification is provided for each input. The goal is to make predictions about new, unseen data based on patterns learned from the training data.Examples of supervised learning include linear regression,
decision trees,and support vector machines.Unsupervised machine learning is a type of machine learning in which the model is not provided with labeled data. Instead,the model is trained on unlabeled data and must find patterns or relationships on its own. The goal is to uncover hidden structures or patterns in the data. Examples of unsupervised learning include clustering, dimensionality reduction, and anomaly detection. Below are the various machine learning projects spanning across various areas such as Regression,classification,Clustering and Time series.

Predicting the price of pizza would depend on various factors such as the location, size, toppings, and competition in the area. It would be difficult to give an accurate prediction without more specific information. However, with the aid of a machine learning algorithm-Linear regression, I was able to predict the price of pizza based on historical data that includes factors such as location, size, and toppings. This algorithm would require a large dataset (gotten from kaggle) and fine-tuning to make accurate predictions

Machine learning can be used to classify mushrooms by training a model on a dataset of mushroom images and their corresponding labels. The model learns to identify patterns and features that distinguish different mushroom species. Once trained, the model can then be used to classify new mushrooms based on their physical characteristics. Common algorithms used for mushroom classification include supervised learning algorithms such as Random Forest, K-Nearest Neighbors (KNN), Support Vector Machines (SVM) and Neural Networks. These algorithms can be trained on various features such as shape, color, size and surface patterns of the mushroom.The link below shows my project link in my github profile.
Time series in machine learning refers to the use of data collected over time, typically at regular intervals, to make predictions about future events based on past events. Techniques used include time series decomposition, forecasting, classification, and clustering. Time series data requires specific techniques to handle temporal dependencies and requires preprocessing steps like handling missing values and removing trend and seasonality. Common models used for forecasting in time series data are ARIMA, SARIMA, LSTM, and Prophet.
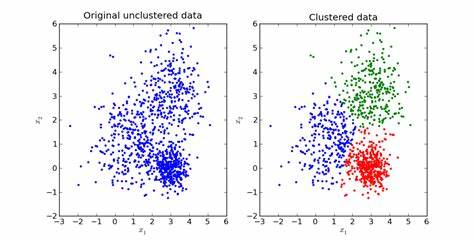
K-means is a clustering algorithm (Unsupervised) that groups similar data points together by iteratively moving centroids to the center of their respective clusters. The basic steps include Initializing k centroids, assigning each data point to the closest centroid, recalculating the centroid of each cluster, and repeating until the centroids no longer move. The algorithm is computationally efficient, easy to understand and implement but has the limitation of assuming spherical clusters and the need to specify the number of clusters in advance. It's sensitive to the initial placement of centroids, so it's common to run the algorithm multiple times with different initial centroids.